
The Job Service is a REST web service that sends operations to workers, checks on the progress of these operations, and allows operations to be cancelled. The following high-level architecture description explains the relationship of the components that work alongside the Job Service to allow for greater control over the tracking and control of background operations. The Job Service is designed to allow wider use of the Worker Framework for complex operations that take a significant length of time to complete.
The figure below illustrates the overall flow and relationship of components in the Job Service.
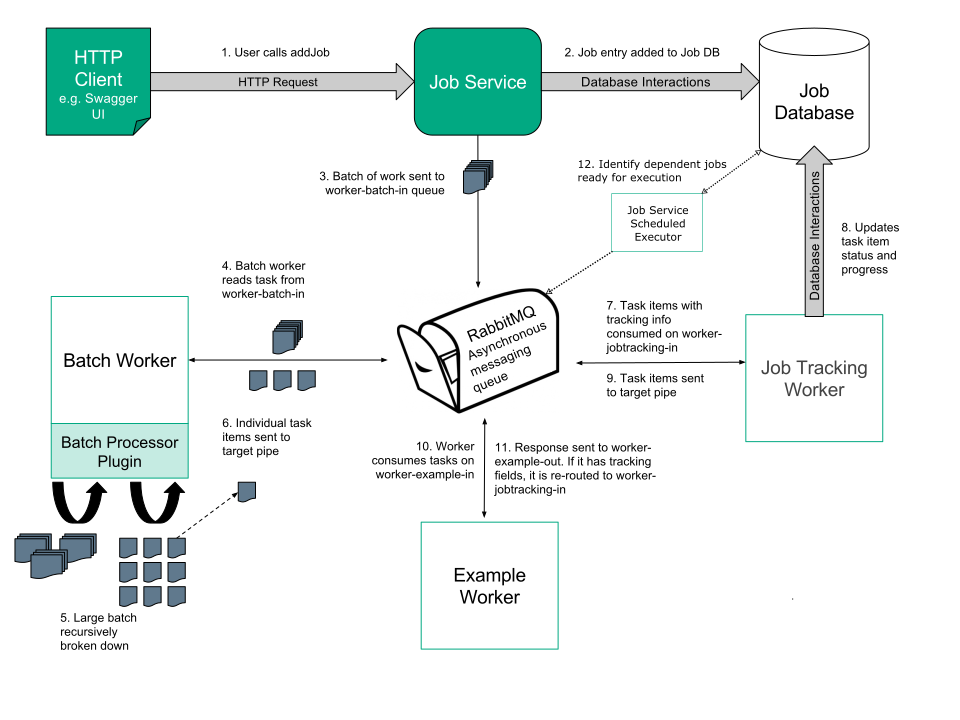
The pipes represent asynchronous message queues on RabbitMQ.
to field is the same as the trackTo field, the task is marked complete in the database and sent to the target pipe without tracking information.
As shown in the figure, the Job Service runs in a container with a base Tomcat image.
It acts as the entry-point for background operations to be initiated, tracked, and cancelled.
Users interact with the Swagger user interface page to make GET, POST, PUT and DELETE HTTP requests to the Job Service, which in turn interacts with the Job Service database and returns responses to the user.
The specification for the Job Service web API is defined in the swagger.yaml file in the job-service-contract project.
The Job Service itself is stateless, which means it can be auto-scaled in future.
The batch worker is an unusual worker because it may dispatch multiple messages for each message it receives. Most workers dispatch a single completion or failure message for each work packet sent to them.
Upon providing a batch processor plugin, a batch can be interpreted by the batch worker, splitting it into smaller batches or individual items of work upon which the service can act. The process of batch splitting is scaled elastically with the autoscaler, allowing sub-batches of a larger batch to process in parallel. The individual items of work emerge and go to the RabbitMQ queue, which is defined in the job and processed by workers. The workers also scale elastically based on the load.
When the batch worker receives a batch to process, it interprets the batch definition string and splits it up into either of the following:
If it splits the batch into a set of smaller batches, then it constructs messages, which are directed back towards itself, and dispatches them to the input pipe to which the batch worker itself listens on (not to the pipe specified by the targetPipe field).
If it instead splits the batch into a set of items, then it generates and dispatches task messages to the targetPipe.
When a worker receives a message for processing, then the Worker Framework first compares the current time to the time specified by summing the lastStatusCheckTime field with the statusCheckIntervalMillis field. If the expiry time has passed, then the statusCheckUrl is used to re-check the job status.
CAF_WORKER_PAUSED_QUEUE.The to field is automatically set by the Worker Framework as the destination pipe, where the sender intends the message to be sent.
After the Worker Framework checks that the task is still active, but before it instantiates the actual worker code, the framework checks the to field to confirm that the message was actually intended for this worker.
to field is set to the pipe that the worker is consuming), then the Worker Framework continues to process the message as normal, using the existing interfaces.to field is not set to the pipe that the worker is consuming), then the Worker Framework re-routes the message to the destination pipe.The job tracking worker is special because it is both:
Messages typically come to the job tracking worker because the pipe from which the worker consumes messages is specified as the trackingPipe. The Worker Framework is triggered to re-route output messages to the job tracking worker, if the tracking fields are present.
When the job tracking worker receives a success message to be proxied (that is, the taskStatus is RESULT_SUCCESS or NEW_TASK and the to field is not the pipe that the worker itself is listening on), then the worker checks whether the trackTo pipe is the same as the to pipe.
The job tracking worker recognizes failure and retry messages, which are being proxied, and updates the job database accordingly.
The job tracking worker can also automatically forward on dependent jobs for execution. A dependent job is a job which must wait until a specific job or list of jobs have completed before it can be executed. The job tracking worker monitors a job’s progress, when a job completes, the job tracking worker will receive a list of jobs which can now be executed.
The Job Service Scheduled Executor is a polling service responsible for identifying and forwarding on dependent jobs for execution which could not be progressed by the Job Tracking Worker because the job had to wait a specified length of time after the jobs it depended on were complete.
The Job Service Scheduled Executor is an ExecutorService which schedules a task to execute repeatedly identifying dependent jobs ready for execution. For each job identified, a message is published on to RabbitMQ to start the job.
Job information is stored in a PostgreSQL database.
This table stores information on the jobs that are requested. Entries are added by the Job Service and updated by the Job Tracking Worker.
| Column | Data Type | Nullable? | Primary Key? |
|---|---|---|---|
| partition_id | varchar(40) | No | Yes |
| job_id | varchar(48) | No | Yes |
| name | varchar(255) | Yes | |
| description | text | Yes | |
| data | text | Yes | |
| create_date | timestamp | No | |
| status | job_status | No | |
| percentage_complete | double | No | |
| failure_details | text | Yes | |
| job_hash | integer | Yes | |
| delay | integer | Yes |
The task tables have the same structure as the job table. Each job has one task table, which is created when the first subtask is reported, and deleted when the job completes successfully. If the job fails, the table is retained for a period of time for examination.
When a task is marked complete, the system checks whether the parent task (or the job if it is the top level) can also be marked complete.
This table stores Ids of dependent jobs i.e. jobs which must be completed before the job in question can be executed.
| Column | Data Type | Nullable? | Primary Key? |
|---|---|---|---|
| partition_id | varchar(40) | No | Yes |
| job_id | varchar(48) | No | Yes |
| dependent_job_id | varchar(48) | No | Yes |
This table stores information on jobs which have dependent jobs and must wait for execution. The table contains enough information for the Job Tracking Worker and Job Service Scheduled Executor to forward on the job, once it’s dependent jobs have all completed.
| Column | Data Type | Nullable? | Primary Key? |
|---|---|---|---|
| partition_id | varchar(40) | No | Yes |
| job_id | varchar(48) | No | Yes |
| task_classifier | varchar(255) | No | |
| task_api_version | integer | No | |
| task_data | byteA | No | |
| task_pipe | varchar(255) | No | |
| target_pipe | varchar(255) | No | |
| eligible_to_run_date | timestamp | Yes |